

AI 代理記憶瓶頸有望突破 RAG 技術成關鍵
分類: AI 產業新聞 發布時間:
人工智慧(AI)代理程式在執行任務時,常面臨記憶體限制,導致效能下降或出現異常。為了解決此問題,一種名為「檢索增強生成」(Retrieval-Augmented Generation,簡稱 RAG)的新技術正受到廣泛關注,有望顯著提升 AI 代理程式的記憶與表現。
RAG 技術的核心概念是將 AI 代理程式的短期記憶(即大型語言模型 LLM 的「上下文視窗」)與外部的長期記憶儲存系統結合。當前的 LLM 模型本身是無狀態的,其上下文視窗的大小有限,一旦資訊超出範圍,代理程式便可能出現故障。RAG 透過將較長期的、較宏觀的資訊儲存在外部系統,並依需求進行檢索,來擴展 AI 的記憶能力。
RAG 的記憶儲存方式主要可分為三種類型:
- 情節記憶 (Episodic Memory):儲存 AI 代理程式過去的決策及其結果,形成「事件流程」,讓代理程式能回溯並學習過往經驗,以指導未來的行動。
- 語意記憶 (Semantic Memory):儲存關於世界和代理程式本身的結構化數據,例如使用者偏好或事實知識。這類記憶可以透過簡單的鍵值對或複雜的向量嵌入來實現,讓代理程式能快速查找並使用這些「世界知識」。
- 程序記憶 (Procedural Memory):專門用於儲存執行特定任務或學習過程的步驟。這使得 AI 代理程式能夠重複執行這些程序,而無需每次都重新學習或建構。
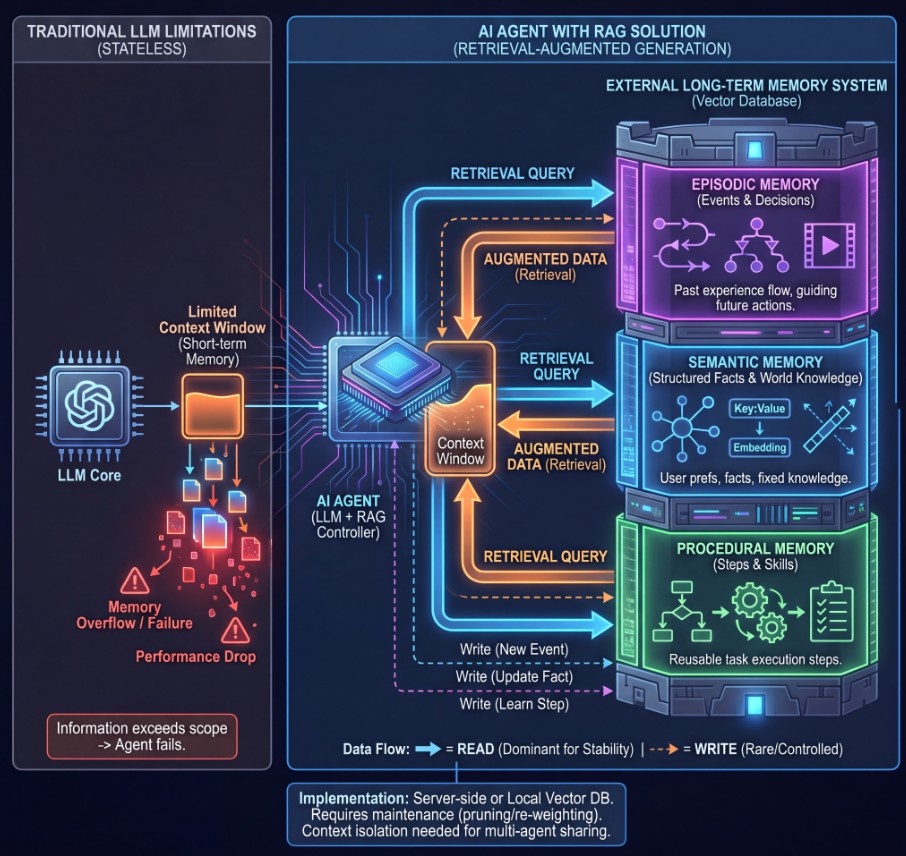
在實施層面,RAG 的儲存層通常採用向量資料庫,許多現代資料庫也支援向量功能。記憶體可以部署在伺服器端,作為 LLM 服務的一部分,或是與本地運行的 LLM 模型部署在同一系統上。然而,後者需要更多的本地儲存空間和處理能力。此外,RAG 儲存系統也需要獨立的維護,例如定期清除舊數據或調整數據權重。雖然多個代理程式可以共享 RAG 儲存,但應確保它們在各自的上下文中運作,以避免數據干擾。