

Cloud Text-to-Speech 技術加入 Google雲端平台
分類: 其他 新品報導 發布時間:
本文作者:雲端人工智慧產品經理 Dan Aharon
許多Google產品(像是Google Assistant、Google搜尋、Google地圖等)都內建了高品質的Text-to-Speech服務,可以產生如人聲般自然的發音。我們收到許多開發者的意見,表示希望能將Text-to-Speech的服務結合到他們的應用程式中,所以今天,我們特別將這項Cloud Text-to-Speech技術加入Google雲端平台(Google Cloud Platform, GCP)中。
使用者可以將Cloud Text-to-Speech服務運用在不同的情境中:
- 為電話語音服務(Interactive Voice Response, IVR)中心提供語音回應系統,並啟用即時自然語言對話功能
- 與物聯網設備,如電視、汽車、機器人等進行對話
- 將文字格式的媒體內容(如新聞文章、書籍)轉為口語形式(如Podcast、有聲書)
Cloud Text-to-Speech服務提供了12種不同語言中的32種不同聲音供使用者選擇。即使是複雜的文字內容,例如姓名、日期、時間、地址等,Cloud Text-to-Speech服務也可以立刻發出準確且道地的發音,並支援多種音檔格式,包含MP3和WAV等,不僅如此,使用者還可以自己調整音調、語速和音量。
[廣告]
Text-to-Speech服務結合DeepMind技術
我們也很開心宣布,Cloud Text-to-Speech服務更以DeepMind所建構的原始音檔生成模型WaveNet為基礎,透過運用WaveNet將一系列高保真度的聲音轉化為語音。整體而言,WaveNet可以合成並產出更自然的語音細節,而且相較於其他Text-to-Speech技術所產生的語音內容,WaveNet所產出的語音內容也更受使用者喜愛。
在2016年底,DeepMind推出了第一版的WaveNet,透過神經網路架構來訓練大量的語音樣本並創造原始音頻的波形。在訓練過程中,神經網路會擷取語音的基本架構,像是語調的連接和語音波形的形狀等。當輸入特定的文字內容時,經過訓練的WaveNet模型會產生相對應的語音波形,藉由一次產生一個樣本的方式,達到比其他方法更高的準確度。
現在,我們使用的運行於Google雲端TPU基礎架構上的更新版WaveNet。全新且升級的WaveNet模型所生成的原始音頻波形比原本的模型快了1,000倍,而且只需50毫秒即可生成一秒鐘的語音訊息。事實上,這個新模型不僅更快速而且具有高保真度,且每秒能創造出24,000個音頻波形的樣本。為了製作出更好、更擬真的音質,我們也將每個樣本的解析度從8位元提高到16位元。
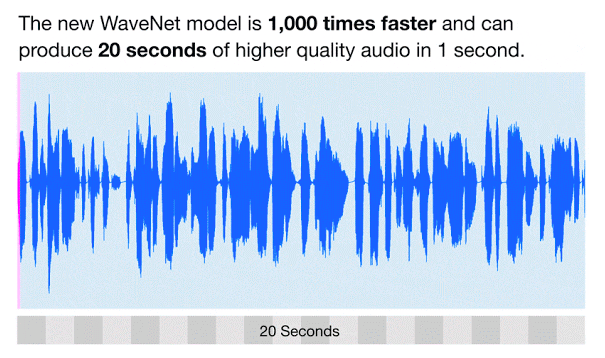
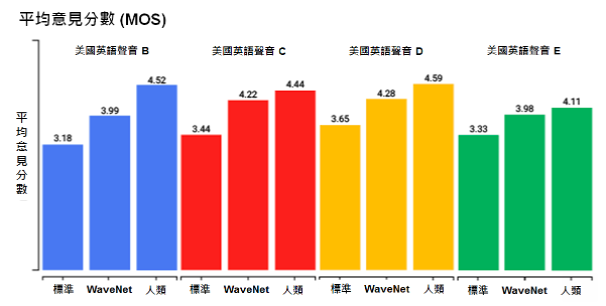
藉由上述調整,新的WaveNet模型可以製作出更自然的語音訊息。在測試過程中,使用者在1到5級的平均意見分數(Mean-opinion-score, MOS)量表中,給予新版美式英文WaveNet語音4.1的高分,其中有超過20%的人認為比標準的人聲更好,而超過70%的人肯定它能降低人類語言的隔閡。由於WaveNet音訊僅需較少錄製音頻,就能製作出高音質模型,因此我們預計在未來幾個月內,將持續改善WaveNet音訊的多樣性與品質,並提供給雲端客戶使用。
Cloud Text-to-Speech已經協助很多我們的客戶,像是思科(Cisco)和Dolphin ONE,提供更好的終端使用者體驗。
「身為提供協作解決方案的領導者,思科長久以來致力於為企業提供最新的技術。Google的Cloud Text-to-Speech服務協助我們提供給客戶他們所期待的自然人聲。」-思科認知協作技術長 Tim Tuttle
「Calll by Dolphin ONE的電信平台在幾乎全球各地都能提供使用者多重設備的連接服務。我們將Cloud Text-to-Speech工具與我們的產品結合,為顧客能體驗到最自然的語音客服。透過使用Google Cloud的機器學習工具,我們能即時將最新科技提供給我們的使用者。」Dolphin ONE, Jason Berryman
馬上開始體驗Text-to-Speech服務
有了Cloud Text-to-Speech服務,你只需要透過點擊就能體驗到全球最先進的語音科技。想瞭解更多詳細資訊,請參考相關文件或價目表;想要試用公開測試版或體驗新的語音服務,請前往Cloud Text-to-Speech的網站。