

AI 模型能力差距持續縮小 中國開源模型在價格與實用性上快速追趕
分類: AI 新品報導 發布時間:
根據 Epoch AI 與 Stanford AI Index 等機構的最新數據,2026 年全球頂尖 AI 模型的能力差距正在明顯縮小。美國頭部實驗室(OpenAI、Anthropic、Google)仍維持領先,但中國多家實驗室推出的模型在多項基準上已接近或達到可比水準,尤其在性價比與實際可用性方面,獲得越來越多業界關注。
頂尖模型實力差距縮小
Epoch AI 能力指數(ECI)顯示,2023 年各家模型分數分佈較為分散,而 2026 年主要模型的分數已明顯集中。Anthropic 的 Claude Fable 5 近期以 161 分取得 ECI 領先,OpenAI 的 GPT-5.5 Pro 緊隨其後(160 分),Google Gemini 3.1 Pro 則位於 156 分左右。
中國模型方面,Qwen 系列、GLM 系列、DeepSeek 與 Kimi 等模型持續在各項基準上取得進展。雖然目前最頂尖的中國模型與美國頭部仍有差距,但這個差距已從過去的明顯領先,縮小到可透過工程優化與應用調整來彌補的範圍。
Stanford AI Index 2026 也指出,中國與美國頂尖模型的性能差距已大幅下降,這反映出中國在模型訓練、資料與演算法優化上的快速進展。
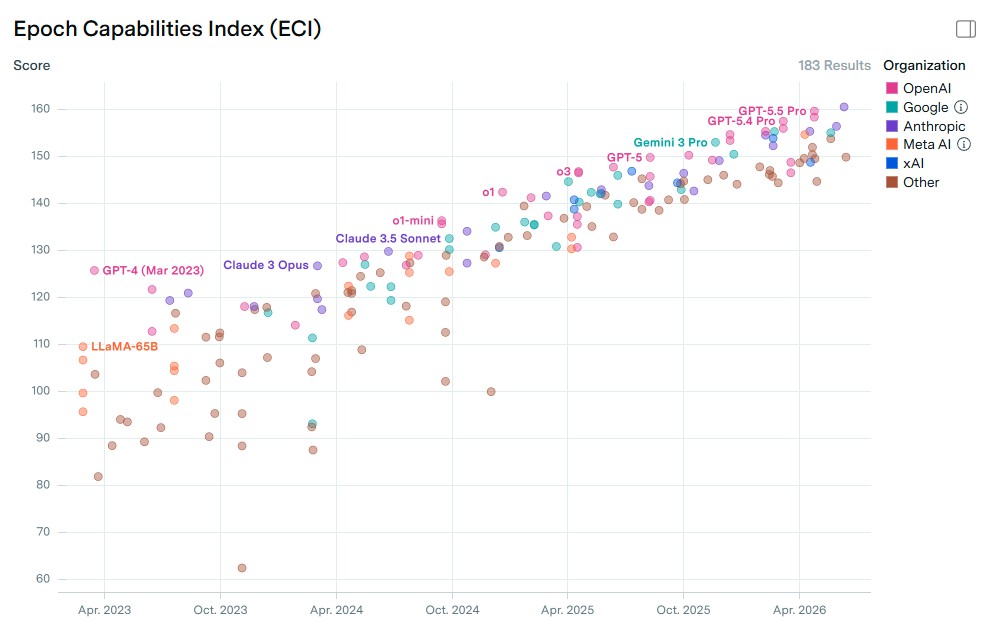
中國模型在性價比與實用性上的優勢
多個業界反饋顯示,中國模型目前最被認可的優勢在於價格與實際可用性的結合。相較於美國頭部模型動輒數倍的 API 價格,中國模型在保持較高性能的同時,價格更具吸引力。
這使得開發者在建構 Agent 系統或大規模應用時,更敢於進行高頻率調用與實驗。部分開發者反饋指出,在相同預算下,使用中國模型能執行更多次迭代與測試,這對需要大量 trial-and-error 的 Agent 開發流程來說,是實質上的優勢。
此外,中國開源模型的可用性也在提升。雖然部分模型在複雜部署上仍有細節需要調整,但整體而言,業界已不再將「中國模型 = 便宜但不好用」視為普遍認知,而是開始認真評估「在特定場景下,哪個模型最划算」。
Agent 技術從「神秘優勢」走向務實討論
2025 年至 2026 年初,美國實驗室在 Agent(尤其是長時程、多步驟任務執行)領域曾被視為明顯領先。然而,隨著中國模型在 Agent 相關基準上的進展,以及業界對 Agent 實際表現的深入使用,相關討論也從「技術領先」轉向「實際效益與成本」。
目前業界對 Agent 的評價趨於兩極:
- 一方面認可其在特定重複性、結構化任務上的效率提升;
- 另一方面也指出,在複雜、需要高度可靠性的場景中,仍常出現成本高、成功率不穩、需要大量人工監督等問題。
中國模型成為業界必須考慮的選項
綜合目前發展,中國開源與低價模型已從「可選」逐漸成為「必須評估」的選項。無論是直接使用中國公司提供的 API 服務,還是部署開源權重,開發者與企業在規劃 AI 應用時,都需要將中國模型納入比較範圍。 這並非意味著美國頭部模型失去優勢,而是在多數非最前沿的應用場景中,性價比與實際可用性已成為重要決策因素。當前市場的共識是:不同模型各有強項,選擇時需根據任務特性、成本預算與部署條件進行綜合評估。
2026 年的 AI 模型競爭格局,呈現出美國頭部實驗室維持技術領先,但中國模型在性能追趕與性價比上快速接近的態勢。隨著更多開發者與企業開始實際大規模使用中國模型,業界對「哪裡的模型最好用」的討論,也從過去的二元對立,轉向更細緻的場景化評估。
參考來源:
Epoch Capabilities Index: https://epoch.ai/eci?view=graph&tab=release-date&subset-view=graph&subset-tab=Software+engineering